Parsing string data is accomplished using the String and StringTokenizer objects. The String object provides a Split method for dividing the string into parts, and the StringTokenizer object breaks the string into tokens which are separated by delimiters (a character or sequence of characters). This page covers the following topics:
For information on parsing files, see the Files page. For information on working with JSON data, see the JSON-Formatted Data page.
Scanning Literal Strings
Literal strings prefixed with the special character @ will be scanned for environment variables and escape sequences.
Escape Sequences
The supported escape sequences are as follows.
Function |
Sequence |
Tab |
\t |
Carriage Return |
\r |
Line Feed |
\n |
Backslash |
\\ |
Dollar Sign |
\$ |
Percent Sign |
\% |
Quotation Mark |
\" |
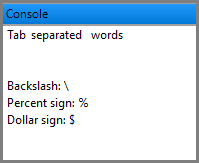
The following example demonstrates how to use the @ symbol to scan a literal string in a Report command for environment variables and escape sequences. The \t and \n sequences are translated to tabs and line feeds, and the backslash, dollar sign, and percent sign are escaped.
Report @"Tab\tseparated\twords\n\n" to Console; Report @"Backslash: \\ \n\"Percent sign\": \% \nDollar sign: \$" to Console; |
Result:
Environment Variables
Environment variables can be evaluated at parse time inside of any literal string scanned using the @ character, using the syntax $(EnvironmentVariableName). This example shows how to report an environment variable called "myEnvironmentVariable" that has been defined on your system:
Report @"My environment variable = $(myEnvironmentVariable)"; |
It is important to note that the value of the environment variable inside a scanned literal string will be evaluated when the Mission Plan is parsed. This means that if you were to change the value of the environment variable in your Mission Plan and then report it inside a scanned string, the original value would be reported; not your updated value. If you want to evaluate the environment variable at runtime, the FF_Preferences.GetEnvironmentVariable("EnvironmentVariableName") method can be used. In the following example, the user changes the value of "myEnvironmentVariable" at the beginning of the script, but the value that is reported in the scanned string will reflect the original value of the environment variable from when the Mission Plan was parsed. The value reported by the GetEnvironmentVariable() method will have the updated value that was specified in script.
// Sets an environment variable called "myEnvironmentVariable" FF_Preferences.SetEnvironmentVariable("myEnvironmentVariable", "C:\myDirectory\v1.0");
// Reports the environment variable inside a scanned string // It will have the original value from when the Mission Plan was parsed Report @"My environment variable = $(myEnvironmentVariable)";
// Reports the environment variable using the GetEnvironmentVariable method, which is evaluated at runtime // It will have the value that the user set at the beginning of the script String envVar; FF_Preferences.GetEnvironmentVariable("myEnvironmentVariable", envVar); Report "My environment variable = " + envVar; |
The ability to access environment variables at parse time is important when the path to a Procedure is set using an environment variable. The Include command needs to evaluate the path to the Procedure when the Mission Plan is parsed. The example below shows how to use the @ symbol to tell FreeFlyer to scan the literal string in an Include statement for environment variables and escape sequences. The $() sequence indicates that the environment variable "myEnvironmentVariable" will be evaluated at parse time. The backslash in the path is escaped using a second backslash. In this example, if "myEnvironmentVariable" has been set to "C:\myDirectory\v1.3", then the Include command will evaluate to include "C:\myDirectory\v1.3\myProcedure.FFProcedure".
Include @"$(myEnvironmentVariable)\\myProcedure.FFProcedure"; |
Splitting a String into Tokens
The StringTokenizer object allows you to split the contents of a String into a StringArray based on the specified delimiter. The following example uses a StringTokenizer object to parse a string and report out the resulting tokens.
Variable i = 0; StringTokenizer st1;
st1.StringToParse = "a::b::c::d,1,2,3::e::f::g";
st1.Delimiters[0] = "::"; st1.Delimiters[1] = ",";
// The Tokens array contains the parsed letters Report st1.Tokens; |
Output Report:
a b c d 1 2 3 e f g |
The StringTokenizer supports multi-character delimiters. This means that you can have overlap between delimiters (e.g. "f" and "fish"). This also means that the StringTokenizer results may depend on the order that the delimiters are applied. The StringTokenizer looks for delimiters starting from the beginning of the string, and if more than one delimiter match is found at a location in the string, the delimiter that comes first in the delimiters array will be used at that location. For example, if you have two delimiters "f" and "fish" matching against "1fish2fish", there are two different possible results, depending on which delimiter appears first in the StringTokenizer.Delimiters property.
If "f" appears first:
StringTokenizer st1;
st1.RemoveDelimiter(" "); st1.AddDelimiter("f"); st1.AddDelimiter("fish");
st1.StringToParse = "1fish2fish"; Report st1.Tokens; |
Output Report:
1 ish2 ish |
If "fish" is first:
StringTokenizer st1;
st1.RemoveDelimiter(" "); st1.AddDelimiter("fish"); st1.AddDelimiter("f");
st1.StringToParse = "1fish2fish"; Report st1.Tokens; |
Output Report:
1 2 |
Regular Expressions as Delimiters
You can also use the StringTokenizer object to parse strings using regular expressions. Use the StringTokenizer.RegularExpression property to set the regular expression to use. FreeFlyer uses regular expressions similar to how Perl uses them. Below is a brief summary of some of the most common regular expressions used.
Expression |
Description |
{n} |
Returns the previous item exactly n times; n>=1 |
{n,} |
Returns the previous item at least n times, looks first for most matches possible; n>=0 |
{n,m} |
Returns the previous item starting with m times before reducing repetition to n times; n>=0, m>=n |
(...){n} |
Matches group (...) if found {n} number of times, if n = 1, {n} is not needed |
[...] |
Matches a single character out of all possibilities offered, special characters will need an escape sequence |
[ - ] |
Hyphen indicates a range of characters, numbers to match; specifies a hyphen if immediately after [ |
[^ ] |
Returns any character except those indicated within brackets |
\Q...\E |
Matches the characters between \Q and \E literally, suppressing the meaning of special characters |
\d |
Matches any decimal digits, can be used inside [...] |
\w |
Matches any word character, can be used inside [...] |
\s |
Matches any whitespace, can be used inside [...] |
\D |
Matches a character that is not a digit, can be used inside [...] |
\W |
Matches a character that is not a word character, can be used inside [...] |
\S |
Matches a character that is not a whitespace, can be used inside [...] |
\n |
Matches a line feed |
\t |
Matches a tab |
Regular expressions also use metacharacters, as described in the table below, to enable more complete delineation of the behavior of the regular expression when used as a delimiter. These characters typically get used alongside the expressions above to specify where a match should happen or how specific characters in the regular expression will be treated by the parser.
Metacharacter |
Description |
\ |
Indicates an escape sequence to suppress special characters |
^ |
Match the beginning of the line |
. |
Match any character except \n (line feed), \r (carriage return) |
$ |
Match the end of the line (or before line feed at the end) |
| |
Alternation |
() |
Grouping |
[] |
Bracketed Character class |
In addition to the metacharacters listed above, certain quantifiers exist that can be used to augment regular expressions by specifying how many of an occurrence to expect. These quantifers are captured in the table below.
Quantifier |
Description |
* |
0 or more of previous expression |
+ |
1 or more of previous expression |
? |
0 or 1 of previous expression |
The following script shows how a String can be parsed using only numbers as delimiters:
Variable i; StringTokenizer st1;
st1.RemoveDelimiter(" "); st1.RegularExpression = "[0-9]";
st1.StringToParse = "red0fish1blue2fish";
Report st1.Tokens; |
Output Report:
red fish blue fish |
A good external resource for more information on the Perl scripting language and regular expressions is: http://perldoc.perl.org/perlre.html#Regular-Expressions
Suppressing Carriage Returns
On Windows, you need to write data in Binary format to be able to suppress Carriage Returns in output files. FreeFlyer supports writing data in Binary as a way to suppress Carriage Returns with the ReportInterface and FileInterface Objects. Below are examples for each Object.
// Suppress Carriage Returns with a ReportInterface ReportInterface ri; ri.Filename = "TestOutput.txt";
Report as Binary @"Test1\n" to ri; Report as Binary @"Test2\n" to ri; Report as Binary @"Test3\n" to ri;
// Suppress Carriage Returns with a FileInterface FileInterface fi; fi.BinaryMode = 1; fi.WriteMode = 1; fi.Filename = "TestOutput.txt"; fi.Open();
// FileInterface Option 1 fi.PutLine("Test1"); fi.PutLine("Test2"); fi.PutLine("Test3"); fi.Close();
// FileInterface Option 2 fi.Write("Test1"); fi.Write(@"\n"); fi.Write("Test2"); fi.Close(); |
Example: Variable.IFormat Method
The following example converts the Integer values "9" and "32" to an ASCII tab character and space character using the Variable.IFormat method. These characters are then added as delimiters to a StringTokenizer Object.
For other ASCII conversion values, consider visiting: http://www.theasciicode.com.ar/
StringTokenizer st1;
Variable charTab = 9; // 9 = horizontal tab Variable charSpace = 32;// 32 = space String strTab = charTab.IFormat("%c"); String strSpace = charSpace.IFormat("%c");
st1.Delimiters[0] = strTab; st1.Delimiters[1] = strSpace;
// Set this to 1 so additional tabs and spaces are captured as one delimiter st1.TreatConsecDelimAsOne = 1;
// Parse the string st1.StringToParse = " tab space tab";
Report st1.Tokens; |
Output Report:
tab space tab |
See Also
•String Properties and Methods
•StringTokenizer Properties and Methods
•Syntax and the FreeForm Script Editor: Inline Strings Section
•Interfacing with Files: Reading Arbitrary File Formats Section